概要
データベースのインデックスは数が多くなるほどテーブルの更新処理 (INSERT / UPDATE) が遅くなるといわれています。また、B-tree インデックスの断片化が進むとキャッシュヒット効率が悪化し、性能に影響を及ぼすとも言われています。
そこで今回は B-tree インデックス(本記事内では「インデックス」と略します)の数と格納する値に着目し、INSERT 処理にどれほど影響するのかを検証しました。
今回の検証は PostgreSQL をターゲットにしており、実装の異なる他のデータベースでは結果の異なる可能性があることにご注意ください。
検証環境
Windows の Hyper-V による仮想マシンを検証環境としました。
ホスト
| プロセッサ | Intel Core i5-6600 CPU @ 3.30GHz |
| メモリ | 20.0 GB |
| SSD | SanDisk SDSSDH3 |
| OS | Windows 10 Pro バージョン 1909 |
Hyper-V
| プロセッサ | 4個の仮想プロセッサ |
| メモリ | 8.0 GB |
| OS | CentOS Linux release 8.2.2004 |
| DB | PostgreSQL 13.1 |
PostgreSQL設定 (postgresql.conf)
デフォルトの設定から変更した箇所を示します。
shared_buffers = 2048MB
full_page_writes = {on | off}full_page_writes は通常のケースでは on とし、一部のケースのみ off で検証しました。
検証方法
以下の条件を組み合わせて測定を行いました。
- インデックスの数
- 0~5 の範囲
- 格納値(テーブルの列に挿入する値)
- 昇順・降順・固定値・ランダム
格納値がランダムのケースにおいてのみ、full_page_writes を on / off の両方で測定しました。
実行時間は EXPLAIN の Execution Time で測定しました。
バッファの使用状況は EXPLAIN の出力で INSERT ノードに出力された値を参照しました。
pgstatindex でインデックスの統計情報を取得しました。
インデックス5個でのスクリプト例を挙げます。
CREATE TABLE tab1 (col1 INTEGER, col2 INTEGER, col3 INTEGER, col4 INTEGER, col5 INTEGER); CREATE INDEX tab1_col1_index ON tab1 (col1); CREATE INDEX tab1_col2_index ON tab1 (col2); CREATE INDEX tab1_col3_index ON tab1 (col3); CREATE INDEX tab1_col4_index ON tab1 (col4); CREATE INDEX tab1_col5_index ON tab1 (col5); BEGIN; SELECT 'index = 5'; -- 以下のいずれかを実行する。 -- 昇順 EXPLAIN (ANALYZE, BUFFERS) INSERT INTO tab1 SELECT val, val, val, val, val FROM generate_series(1, 10000000) val; -- 降順 EXPLAIN (ANALYZE, BUFFERS) INSERT INTO tab1 SELECT (10000000 - val), (10000000 - val), (10000000 - val), (10000000 - val), (10000000 - val) FROM generate_series(1, 10000000) val; -- 固定値 EXPLAIN (ANALYZE, BUFFERS) INSERT INTO tab1 SELECT 1, 1, 1, 1, 1 FROM generate_series(1, 10000000); -- ランダム SELECT setseed(0); EXPLAIN (ANALYZE, BUFFERS) INSERT INTO tab1 SELECT random.val, random.val, random.val, random.val, random.val FROM (SELECT floor(random() * 10000000) val FROM generate_series(1, 10000000)) random; COMMIT; SELECT * FROM pgstatindex('tab1_col1_index'); SELECT * FROM pgstatindex('tab1_col2_index'); SELECT * FROM pgstatindex('tab1_col3_index'); SELECT * FROM pgstatindex('tab1_col4_index'); SELECT * FROM pgstatindex('tab1_col5_index'); DROP TABLE tab1;
検証結果
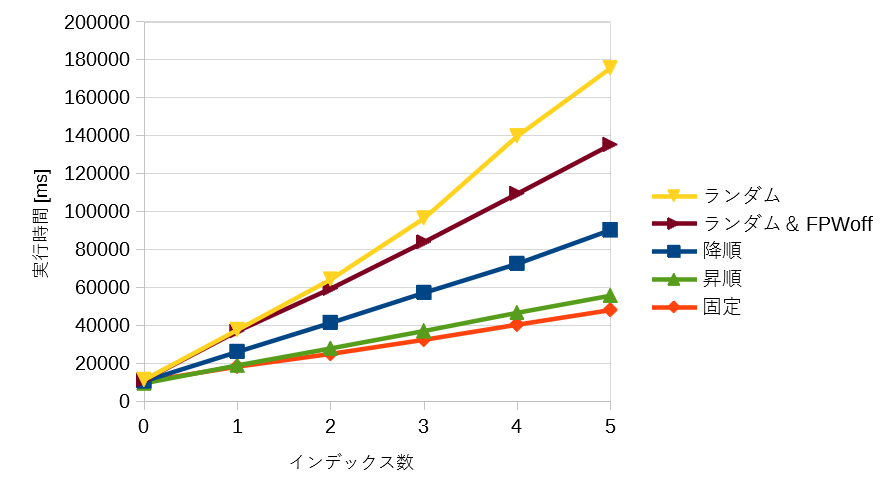
<図1 インデックス数・格納値別 実行時間>
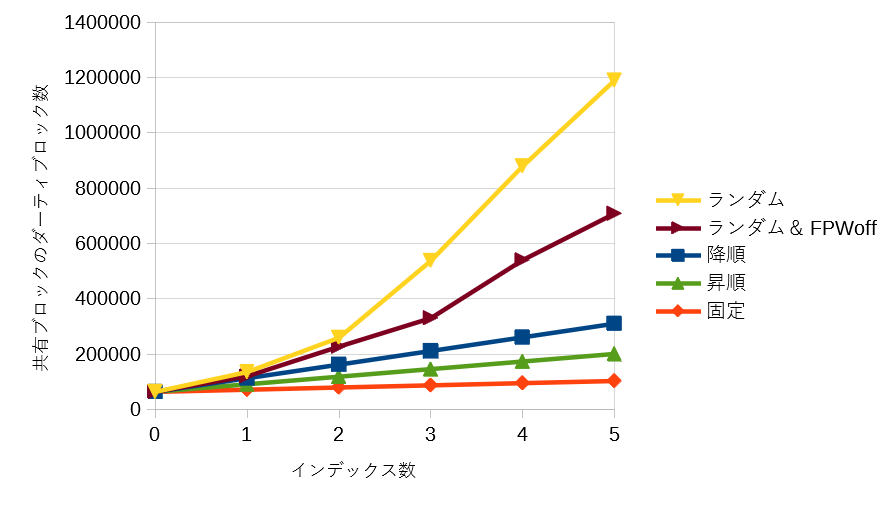
<図2 インデックス数・格納値別 共有ブロックのダーティブロック数>
| 格納値 | version | tree_level | index_size | root_block_no | internal_pages | leaf_pages | empty_pages | deleted_pages | avg_leaf_density | leaf_fragmentation |
| ランダム | 4 | 2 | 265,527,296 | 412 | 108 | 32,304 | 0 | 0 | 70.57 | 49.87 |
| 降順 | 4 | 2 | 403,554,304 | 412 | 241 | 49,020 | 0 | 0 | 50.34 | 100 |
| 昇順 | 4 | 2 | 224,632,832 | 412 | 97 | 27,323 | 0 | 0 | 90.09 | 0 |
| 固定 | 4 | 2 | 64,430,080 | 295 | 39 | 7,825 | 0 | 0 | 96.17 | 0 |
<表1 インデックスの統計情報>
図1から以下のことが分かりました。
- インデックスの数が増えるほど INSERT 処理は遅くなる。
- インデックスの更新時間は 固定 < 昇順 < 降順 < ランダム&FPWoff(※) < ランダム となる。
(※)FPWoff は full_page_writes = off です。
格納値の種類によってインデックス有りの実行時間(≒インデックスの更新時間)が異なったのは、インデックスのページ分割が影響したと推測しています。
テーブルにデータを挿入していくと、インデックスには該当列のデータ(キー)がリーフページに挿入されていきます。インデックスのあるページがいっぱいになると、左右2つのページに分割 (SPLIT) されます。特殊なケースを除き、SPLIT が起こるとデータ量は左のページに 50%、右のページに 50% のデータ量になるように分割されます。このようにデータを分割して格納するため、断片化が起こります。
(中略)
なお、木構造の各段の一番右端ページで SPLIT が起こるケースでは、左のページにできるだけ詰めた形で分割します。このため昇順にデータが追加されるインデックスであれば、断片化の影響を避けられます。
[改訂新版]内部構造から学ぶPostgreSQL 設計・運用計画の鉄則 (Software Design plus)
表1より、昇順や固定では断片化 (leaf_fragmentation) が起きていませんが、降順やランダムでは断片化が起きたと分かります。
ランダムでの結果が悪いのは full-page write が影響していることを示唆する記事がありました。
Of course, this is due to the inherent UUID randomness. With BIGSERIAL new are sequential, and so get inserted to the same leaf pages in the btree index. As only the first modification to a page triggers the full-page write, only a tiny fraction of the WAL records are FPIs. With UUID it's completely different case, of couse – the values are not sequential at all, in fact each insert is likely to touch completely new leaf index leaf page (assuming the index is large enough).
On the impact of full-page writes - 2ndQuadrant | PostgreSQL
そこで、full-page write を off にしたところ、実行時間が短縮されました(図1)。
格納値の種類の違いによる実行時間の差異は共有ブロックのダーティブロック数と相関がありそうです(図2)。共有ブロック変更の内訳が分かれば実行時間の差異を説明できるかもしれませんが、これを調べるための手法が見つかりませんでした。
まとめ
今回の検証からは以下のことが分かりました。
- インデックスの数が増えるほど INSERT 処理は遅くなる。
- インデックスの更新時間は 固定 < 昇順 < 降順 < ランダム&FPWoff < ランダム となる。
今回の検証では格納値の種類と実行時間の関係について、インデックスのページ分割が影響していると推測したものの、理論による裏付けを明確に示すには至りませんでした。これは今後の課題とします。