概要
PostgreSQL には HOT (Heap-Only Tuples) という、更新のオーバーヘッドを減らす仕組みがあります。詳細は下記の記事を参照ください。
HOTの活用 | Let's POSTGRES
HOT 更新には条件があり、その一つが「HOT更新のための十分なページ領域」です。テーブルの fillfactor(以下、FF)を下げると、ページ内に空き領域を残しやすくなり、HOT 更新が発生しやすくなります。
テーブルのfillfactorを減らすことで、HOT更新のための十分なページ領域の可能性を高めることができます。 そうしない場合でも、HOT更新は発生します。 なぜなら、新しい行は新しいページや、新しい行バージョンのために十分な空き領域を持つ既存のページに自然に移動するからです。
66.7. ヒープ専用タプル(HOT)
PostgreSQL 18 時点で、テーブルの fillfactor のデフォルトは100(可能な限りページを詰める)です。
また、次のような記載もあります。
一般的には、FILLFACTOR=90でHOTが十分に機能するでしょう。
なお、FILLFACTORを設定すると空き領域をテーブルデータ内に作ることになるため、テーブルデータの密度が下がります。密度が下がると、読み込むデータ量が増えます(キャッシュヒット率の低下)。そのため、INSERT、SELECT処理がメインとなるテーブルについては、キャッシュヒット率を重視する意味で、FILLFACTORは指定せず、デフォルトである 100% の設定を使うほうが良いでしょう。
第三回 HOTの上手な使い方 | Let's POSTGRES
つまり、FFの調整には「HOT更新しやすくなる」メリットと、「テーブルが肥大化しやすくなり読み取りが不利になる」デメリットがあり、トレードオフになります。本記事では、このトレードオフを実験で確認します。
検証環境
Windows 11 マシンの Hyper-V 環境で検証しました。
ホスト
| プロセッサ | Intel Core i5-14500 |
|---|---|
| メモリー | 32 GB |
| OS | Windows 11 Pro 25H2 |
Hyper-V
| プロセッサ | 10個の仮想プロセッサ |
|---|---|
| メモリー | 8 GB |
| OS | Rocky Linux release 9.7 |
| DB | PostgreSQL 18.2 |
検証コード/設定
検証コード及び設定は GitHub に格納しました。
GitHub - pato-taityo/fillfactor_effect
検証コードは ChatGPT で生成し、活用した部分については妥当性を確認しました。ただし、未活用の部分については十分な精査をしていません。
検証に用いた postgresql.conf も格納しています。
検証環境(10 vCPU VM)を踏まえ、並列度は次の値に変更しています。
export CLIENTS=20 export JOBS=10
検証
TPC-B(pgbenchの組み込みシナリオ)
pgbench の TPC-B に基づいたシナリオを使い、FF を 100 から 70 まで変化させて TPS を測定しました。
FF と TPS を比較した結果を示します。
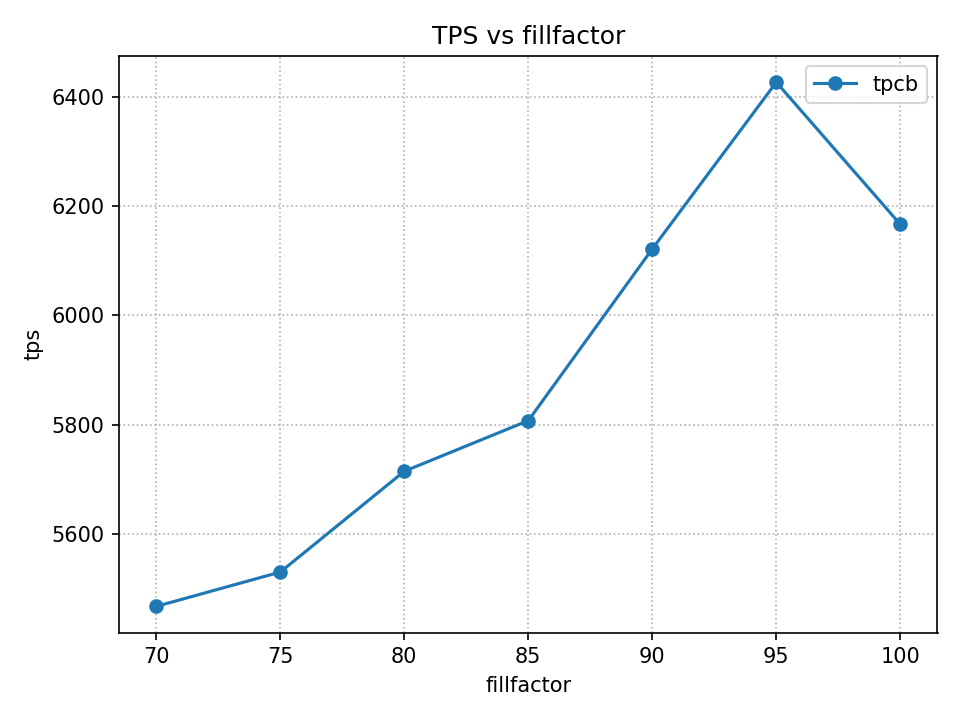
TPS に注目すると、FF=100 より FF=95 が良い結果となりました。ですが、FF<=90 では FF=100 よりも悪い結果となっています。
この結果を pgbench_accounts テーブルに着目して分析します。
pg_stat_all_tables の統計情報から、更新全体 (n_tup_upd) のうち HOT 更新 (n_tup_hot_upd) が占める割合を、HOT更新率の近似値として扱います(※統計値は累積なので、測定開始・終了時点の差分で見ています)。その結果を FF と比較したものが次です。
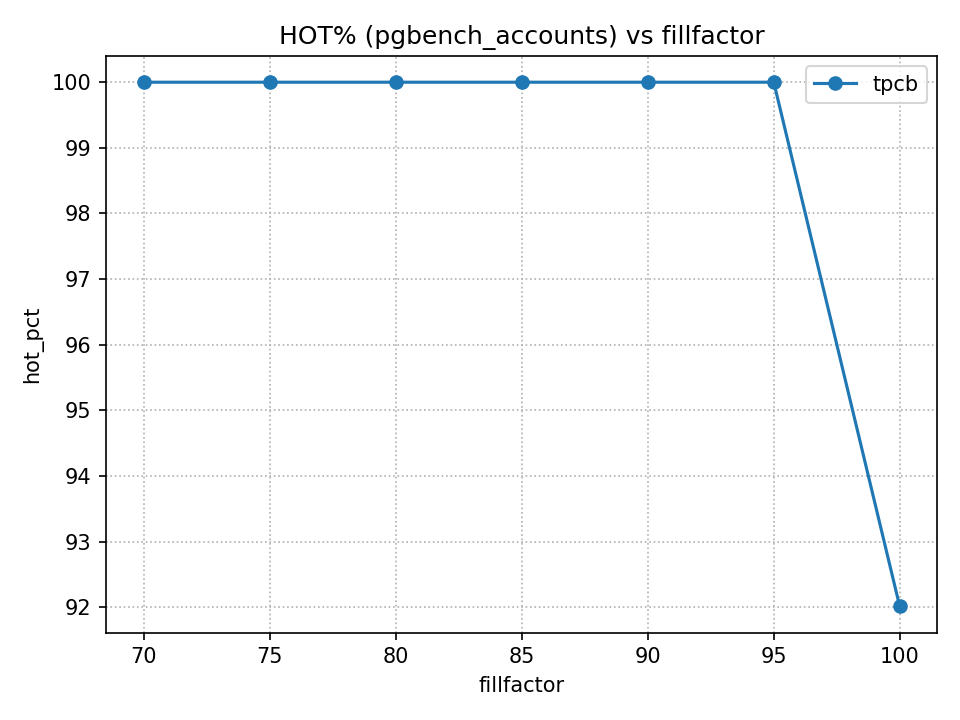
FF=95 の時点でほぼすべてが HOT 更新となっており、FF をさらに下げても「HOT更新率の改善」という観点では伸びしろが小さい状況でした。
一方で、pgbench_accounts テーブルのサイズは FF を下げるほど増大します。
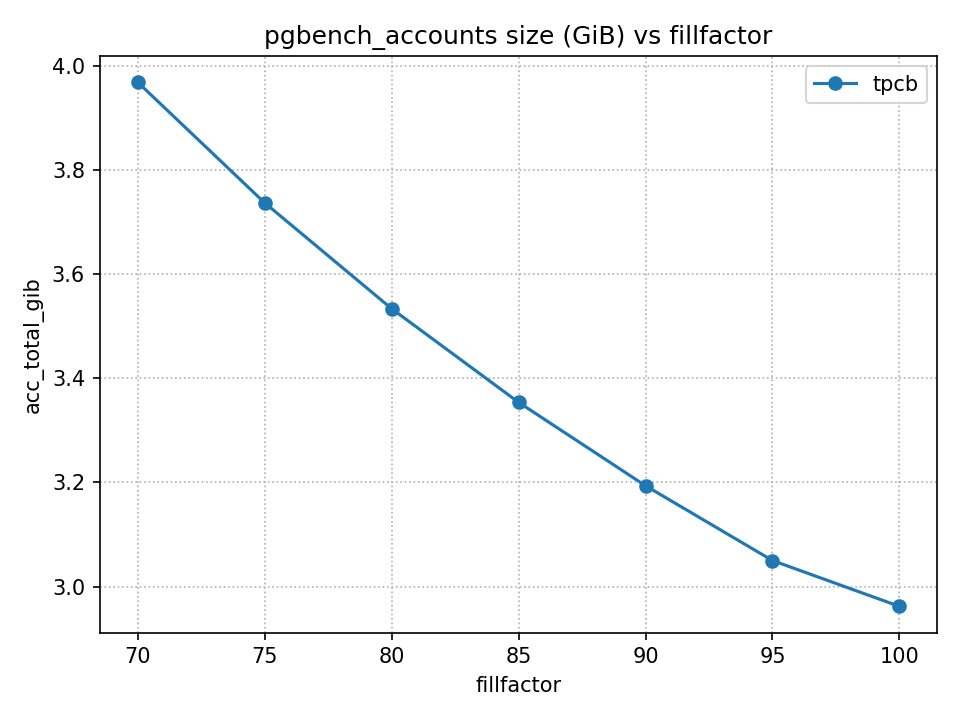
テーブルサイズが増えると、同じ件数を扱っていても必要なページ数が増え、キャッシュヒット率の低下などを通じて読み取りが不利になります。
以上より、今回の検証環境下では、
- FF=95 は HOT 更新の改善効果が有利に働き TPS が向上した
- しかし FF を下げすぎると、テーブル肥大による悪影響が支配的になり TPS が低下した
と解釈できます。
DML単体の影響
TPC-B は複合的なシナリオだったため、次に DML 単体(SELECT / INSERT / UPDATE / DELETE)と FF の影響を確認します。
UPDATE については、HOT 更新の影響が比較しやすいように、HOT 更新が起こりにくい条件を作った update_nohot も用意しました(インデックスを設定した列を更新し、HOT更新が起こらないようにしています)。
また、UPDATE の代わりに DELETE + INSERT を行う churn と名付けたテストも含めています。
DELETE を単純に「ランダムな aid を消す」という実装にすると、時間が進むにつれて「DELETE がヒットしない(0行削除)」が増える懸念があります。そこで、pgbench_delete_queue (UNLOGGED TABLE) を用意し、DELETE が必ず既存行を削除する実装にしました。
FF と TPS を比較した結果を示します。見やすくするため、各 DML の FF=100 を基準に正規化しています。
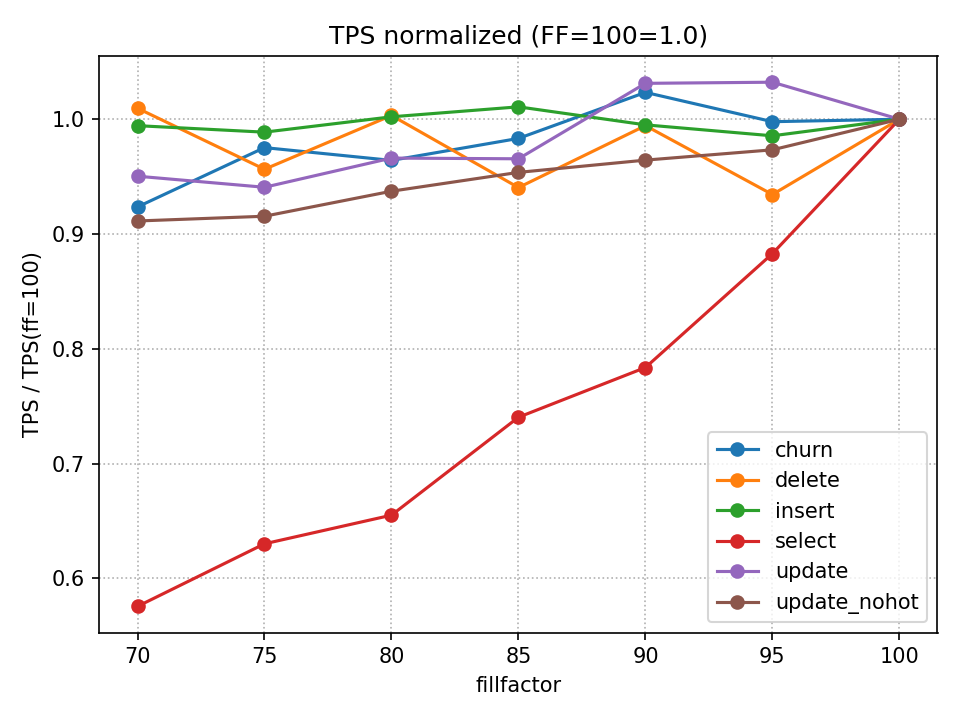
FF を低下させるに従い、概ね以下の結果となりました。
- SELECT は TPS が著しく落ちました。FF 低下によりテーブルが肥大化し、キャッシュ効率が悪化した影響が大きいと推測しています。
- UPDATE(HOT更新あり)は FF=90, 95 で TPS 向上が見られました。ただし改善幅は小さめで、FF<=85 では FF=100 を下回りました。
- UPDATE(HOT更新なし)は、FF を下げるほど TPS が低下しました。HOT 更新のメリットが得られない一方で、テーブル肥大のデメリットは受けるためと考えられます。
- INSERT はほぼ横ばいでした(少なくとも今回の条件では FF の影響は限定的でした)。
- DELETE は ±数%程度の揺れに収まり、単回測定の範囲では明確な傾向を断定しにくい結果でした。
これらを踏まえると、FF を低下させて「全体としての性能向上」を狙うには、相当量の UPDATE があり、かつ HOT 更新が十分に見込めるワークロードでない限り難しい(少なくとも今回の条件ではそう見える)と言えそうです。
結論
実際のワークロード次第ではありますが、FF を見直して効果を得られるのは、HOT 更新の改善がボトルネックに効いてくるケースに限られそうです。
また、FF=100 でも HOT 更新は起こりうることを考えると、確証が持てない段階ではデフォルト(FF=100)で様子を見る判断も現実的だと思われます。
こぼれ話
今回の検証では AI (ChatGPT) との共同作業で行いました。AI は実験計画と検証コードを素早く準備し、検証をサポートしてくれました。また、私だけでは思いつかなかったような観点もフォローしてくれました。
ただ一方で、検証としては致命的なミスを犯すこともあり、それ故に違和感のある結果が出たとしても、無理やり説明をつけて正当化しようとする場面もありました。
AI は頼りになる味方ですが、それでも出力結果に対して批判的にチェックすべきということを忘れてはならない、と改めて感じる機会となりました。