概要
Windows 10 の Hyper-V 上で稼働する仮想マシンにて、PostgreSQL のベンチマークを測定していました。すると、1 CPU より 2 CPU で動作する時に大きく性能劣化してしまいました。これはハイパーバイザースケジューラである「ルートスケジューラ」に原因があるのでは…?と推測しています。検証結果をまとめます。
検証環境
Hyper-V
| プロセッサ | 4個の仮想プロセッサ |
|---|---|
| OS | Red Hat Enterprise Linux release 8.6 |
PostgreSQL
PostgreSQL 14.5 をソースコードからインストールしました。
事象
PostgreSQL のベンチマークツールである pgbench で、"SELECT 1;" というシンプルなクエリを実行して TPS を測定しました。すると、PostgreSQL と pgbench を同一 CPU で動作させるか、異なる CPU で動作させるかによって TPS に顕著な違いが現れました。
-- select1.pgbench ファイルの中身 SELECT 1;
-- 同一 CPU で動作 $ taskset -c 0 pg_ctl start -D /usr/local/pgsql/data/ $ taskset -c 0 pgbench -f /home/postgres/select1.pgbench -c 1 -j 1 -n -T 180 testdb -- 異なる CPU で動作 $ taskset -c 0 pg_ctl start -D /usr/local/pgsql/data/ $ taskset -c 1 pgbench -f /home/postgres/select1.pgbench -c 1 -j 1 -n -T 180 testdb
| 動作 CPU | TPS |
|---|---|
| 同一 | 6,507,144 |
| 異なる | 1,787,641 |
PostgreSQL と pgbench を同一 CPU で動作させた方が高い TPS となりました。直感的には異なる CPU で動作させた方がパフォーマンスは良くなりそうですが、これに反する結果となりました。
調査と結論
パフォーマンスモニターで Hyper-V の CPU 使用率を調べることができます。
パフォーマンス・モニタでHyper-Vサーバの実際のCPU使用率を調査する − @IT
また、CPU 使用率以外にも様々なメトリクスを取得できます。今回は "Hyper-V Hypervisor Logical Processor" カテゴリの以下のカウンタに注目しました。
- % Total Run Time
- % Guest Run Time
- % Hypervisor Run Time
- Context Switches/sec
論理プロセッサ別・1秒間隔で測定を行いました。以下にグラフを示します。







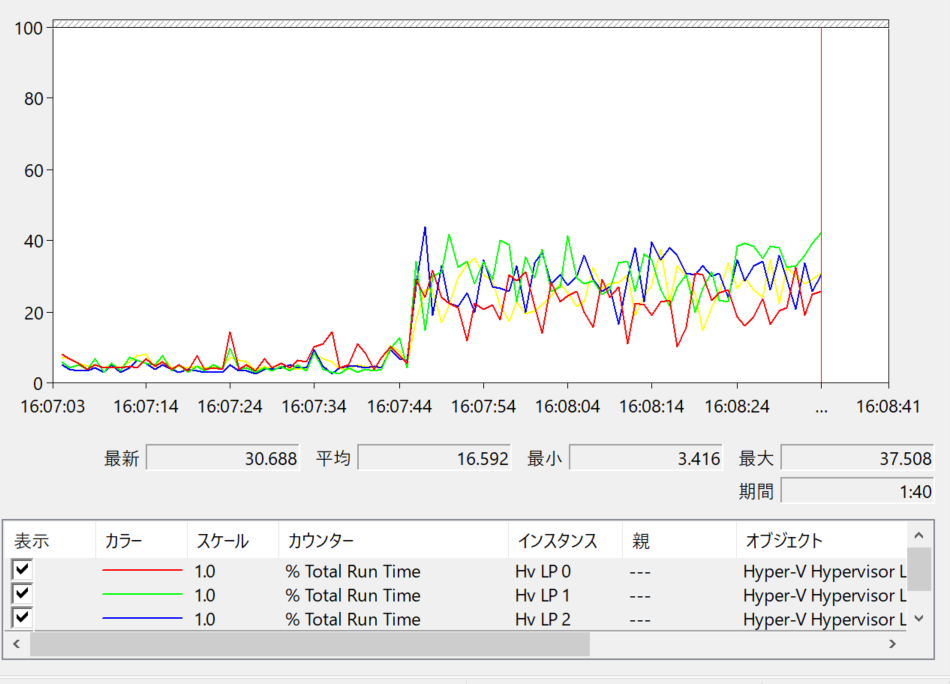
同一 CPU で動作した時は論理プロセッサに対してまんべんなく分散されているようにみえます。Hypervisor Run Time は低く、コンテキストスイッチも少ないです。
一方、異なる CPU で動作させたときは論理プロセッサの負荷に偏りが見られます。負荷が集中した論理プロセッサの Hypervisor Run Time は高く、コンテキストスイッチも多くなっています。
論理プロセッサの負荷の偏りが異なる CPU で動作させたときに必ず起きる事象なのかを確認するため、CPU ベンチマークを実行して同様の測定を行いました。
taskset -c 0 stress-ng -c 1 -l 100 taskset -c 1 stress-ng -c 1 -l 100
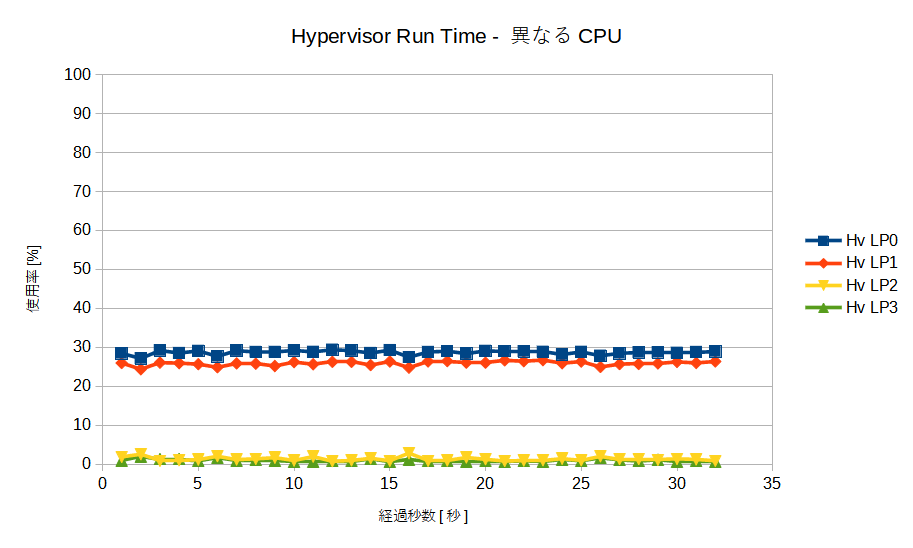
測定結果のグラフを示します。




これらのグラフからは以下のことが言えます。
- 負荷は論理プロセッサに対してまんべんなく分散されている
- Hypervisor Run Time は低い
- コンテキストスイッチも少ない
ここまでの結果から、特定のワークロードにおいて論理プロセッサの負荷分散を上手くできないケースがあると推測しました。
Hyper-V Hypervisor のさまざまな種類のスケジューラを理解して使用する | Microsoft Learn
この記事を参考に Hyper-V のハイパーバイザースケジューラの種類を確認しました。
PS > Get-WinEvent -FilterHashTable @{ProviderName="Microsoft-Windows-Hyper-V-Hypervisor"; ID=2} -MaxEvents 1
ProviderName: Microsoft-Windows-Hyper-V-Hypervisor
TimeCreated Id LevelDisplayName Message
----------- -- ---------------- -------
2022/10/30 10:55:54 2 情報 Hypervisor scheduler type is 0x4.今回の環境では「ルートスケジューラ」が選択されているとわかります。
ルートスケジューラについて下記の記載があります。
サーバー システムでのルート スケジューラの使用
Hyper-V Hypervisor のさまざまな種類のスケジューラを理解して使用する | Microsoft Learn
現時点では、サーバー上の Hyper-V でのルート スケジューラの使用は推奨されていません。これは、多くのサーバー仮想化のデプロイで一般的なさまざまなワークロードに対応するためのパフォーマンス特性がまだ完全に特徴付けられたり調整されていないためです。
このことから、ルートスケジューラの調整が不十分なために今回の事象が発生した可能性もあるのでは…?とみています。
問題の切り分けのためには他のスケジューラで検証したいところですが、下記の記載がありました。
クライアント システムでのルート スケジューラの使用
Hyper-V Hypervisor のさまざまな種類のスケジューラを理解して使用する | Microsoft Learn
Windows 10 バージョン1803以降、クライアント システムではルート スケジューラが既定で使用されます。クライアント システムでは、ハイパーバイザーを有効にすると、仮想化ベースのセキュリティと WDAG ワークロードの分離がサポートされ、異種のコア アーキテクチャを使用する今後のシステムを適切に運用できます。 これは、クライアント システムでサポートされる唯一のハイパーバイザー スケジューラの構成です。 管理者は Windows 10 クライアント システムで既定のハイパーバイザー スケジューラの種類を上書きすべきではありません。
手元で検証に利用可能な環境がなく、今回は見送ることにしました。確証を得られなかったことは残念です。
調査補足
ハイパーバイザースケジューラの問題ではないか、という結論に至るまでは試行錯誤がありました。その過程の一部をお見せすることは今回の事象を理解する参考になると考え、以下にまとめます。
今回調査するに至ったきっかけは、PostgreSQL+ベンチマークツールを動作させたとき、CPU に余計な負荷をかけた時の結果が良いと気づいたことでした。
$ pgbench -i -s 32 testdb $ pgbench -c 1 -j 1 -S -T 180 testdb -- CPU に余計な負荷をかける場合は以下のコマンドを実行する。 # stress-ng -c 3 -l 100
| 条件 | TPS |
|---|---|
| 負荷なし | 7486.170541 |
| 負荷あり | 15680.693977 |
仮想マシンに割り当てる CPU の数を変化させてみると、1 個で最も結果が良く、複数個では結果が悪くなりました。
$ pgbench -i -s 32 testdb $ pgbench -c 1 -j 1 -S -T 180 testdb
| CPU数 | TPS |
|---|---|
| 1 | 17841.700461 |
| 2 | 7485.412947 |
| 3 | 7522.999178 |
| 4 | 7486.170541 |
ベンチマークのシナリオに問題があるのではと考え、"SELECT 1;" というシンプルなクエリで試しましたが、PostgreSQL と pgbench への CPU の割り当て方で差が出たのは先述の通りです。
プロセスへの CPU の割り当て方でパフォーマンスが変わるのであれば、コンテキストスイッチが悪さをしているのではないかと推測しました。そこで、perf で調査を行いました。
-- 同一 CPU で動作 $ taskset -c 0 pg_ctl start -D /usr/local/pgsql/data/ $ taskset -c 0 pgbench -f /home/postgres/select1.pgbench -c 1 -j 1 -n -T 180 testdb -- 異なる CPU で動作 $ taskset -c 0 pg_ctl start -D /usr/local/pgsql/data/ $ taskset -c 1 pgbench -f /home/postgres/select1.pgbench -c 1 -j 1 -n -T 180 testdb -- バックエンドプロセスの pid を調べる # ps aux | grep postgres # perf stat -p <バックエンドプロセスの pid> sleep 10
perf stat の結果を示します。
-- 同一 CPU で動作
5,971.10 msec task-clock # 0.597 CPUs utilized
179,280 context-switches # 30.025 K/sec
0 cpu-migrations # 0.000 /sec
0 page-faults # 0.000 /sec
17,564,682,664 cycles # 2.942 GHz
8,420,378,120 instructions # 0.48 insn per cycle
1,790,710,601 branches # 299.896 M/sec
21,018,291 branch-misses # 1.17% of all branches
-- 異なる CPU で動作
7,456.07 msec task-clock # 0.745 CPUs utilized
113,125 context-switches # 15.172 K/sec
0 cpu-migrations # 0.000 /sec
0 page-faults # 0.000 /sec
13,385,326,996 cycles # 1.795 GHz
5,310,518,873 instructions # 0.40 insn per cycle
1,128,762,018 branches # 151.388 M/sec
34,475,930 branch-misses # 3.05% of all branchesコンテキストスイッチの頻度だけを見れば、異なる CPU のほうが少ない結果となりました。ただ、cycles の値も小さいのが気になりました。
perf record / report での分析も行いましたが、ここからは差異を見出すことができませんでした。
CPU 毎の使用率を調べてみました。
-- 同一 CPU で動作 $ taskset -c 0 pg_ctl start -D /usr/local/pgsql/data/ $ taskset -c 0 pgbench -f /home/postgres/select1.pgbench -c 1 -j 1 -n -T 180 testdb -- 異なる CPU で動作 $ taskset -c 0 pg_ctl start -D /usr/local/pgsql/data/ $ taskset -c 1 pgbench -f /home/postgres/select1.pgbench -c 1 -j 1 -n -T 180 testdb # mpstat -P ALL 1
-- 同一 CPU で動作 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle all 14.50 0.00 10.25 0.00 0.25 0.00 0.00 0.00 0.00 75.00 0 58.00 0.00 41.00 0.00 1.00 0.00 0.00 0.00 0.00 0.00 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 -- 異なる CPU で動作 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle all 8.88 0.00 17.26 0.00 0.00 0.00 0.00 0.00 0.00 73.86 0 26.80 0.00 36.08 0.00 0.00 0.00 0.00 0.00 0.00 37.11 1 9.38 0.00 33.33 0.00 0.00 0.00 0.00 0.00 0.00 57.29 2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 3 0.00 0.00 0.99 0.00 0.00 0.00 0.00 0.00 0.00 99.01
いずれの場合にも CPU には余裕があるように見えます。そこで、PostgreSQL の待機イベントに違いが見いだせないかを調べました。待機イベントの調査には pg_wait_sampling (GitHub - postgrespro/pg_wait_sampling: Sampling based statistics of wait events) を利用しました。
$ taskset -c 0 pg_ctl start -D /usr/local/pgsql/data/ $ psql -d testdb -c 'SELECT pg_wait_sampling_reset_profile();' -- 同一 CPU で動作 $ taskset -c 0 pgbench -f /home/postgres/select1.pgbench -c 1 -j 1 -n -T 180 testdb -- 異なる CPU で動作 $ taskset -c 1 pgbench -f /home/postgres/select1.pgbench -c 1 -j 1 -n -T 180 testdb $ psql --csv -d testdb -c "SELECT event_type, event, SUM(count) AS sum_event FROM pg_wait_sampling_profile WHERE event IS NOT NULL GROUP BY event_type, event ORDER BY sum_event desc;"
-- 同一 CPU で動作 event_type,event,sum_event Activity,LogicalLauncherMain,19491 Activity,CheckpointerMain,19491 Activity,WalWriterMain,19489 Client,ClientRead,17852 Activity,BgWriterMain,11355 Activity,BgWriterHibernate,8136 IO,DataFileRead,2 IO,WALSync,1 -- 異なる CPU で動作 event_type,event,sum_event Activity,CheckpointerMain,19171 Activity,LogicalLauncherMain,19171 Activity,WalWriterMain,19170 Activity,BgWriterHibernate,18798 Client,ClientRead,17823 Activity,BgWriterMain,373 IO,WALSync,1
BgWriterMain, BgWriterHibernate で差異があるように見えますが、どちらもバックグラウンドライタプロセスの待機イベントであることを踏まえ、足し合わせた値で比較すると、差異がほとんどないとわかります。
その他、様々な試行錯誤を行いましたが、仮想マシン上で取得できる情報から原因を見出すことができませんでした。そして、最終的にパフォーマンスモニタで Hyper-V の情報を取得できることに気づき、調査して先述の結論にたどり着きました。