PostgreSQL のボトルネック調査に待機イベントを活用する
概要
PostgreSQL 9.6 以降では pg_stat_activity ビューに wait_event_type, wait_event が導入されました。これらの列ではバックエンドが待機しているイベントの情報を確認できます。この待機イベントの情報を収集することで、PostgreSQL のボトルネック調査に役立つかもしれません。
事例
pgbench でパフォーマンスの検証を行っていたところ、以下の事象が見つかりました。
- クライアント数に対して TPS が直線的に増加しない
- クライアント数に対して latency が直線的に増加する
- CPU は余力 (vmstat の id) がある
- CPU の I/O 待ち (vmstat の wa) は 10% 以下
- ディスクにも余力がありそう (iostat の %util は 100% 近いが他の指標より判断した)
TPS, latency, CPU (us, sy, id, wa) のグラフを示します。
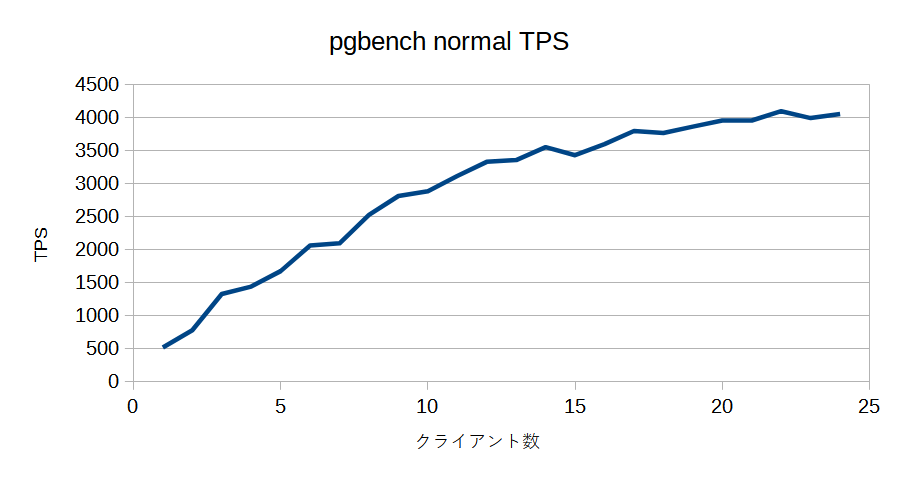


また、以下の条件では CPU の性能限界まで TPS が直線的な増加をしました。
- pgbench の --unlogged-tables オプションを指定する
- pgbench の --select-only オプションを指定する
- postgresql.conf で synchronous_commit = off を指定する
unlogged-tables の例で先ほどと同様のグラフを示します。



この結果を踏まえると、WAL 書き込みがボトルネックになっていると推測できます。
今回は検証なので異なる条件での比較検討が容易でしたが、本番環境で同じ問題が起きた時に条件を変えて比較することは困難です。そこで、今回のような事象が起きた時にボトルネックを見抜く手段の一つとして、待機イベントの情報収集という方法が有用かを確認しました。
検証環境
Windows の Hyper-V による仮想マシンを検証環境としました。
ホスト
| プロセッサ | Intel Core i5-6600 CPU @ 3.30GHz |
|---|---|
| メモリ | 20.0 GB |
| SSD | SanDisk SDSSDH3 |
| OS | Windows 10 Pro バージョン 21H2 |
Hyper-V
| プロセッサ | 4個の仮想プロセッサ |
|---|---|
| メモリ | 8.0 GB |
| OS | Red Hat Enterprise Linux release 8.6 |
PostgreSQL
PostgreSQL 14.5 をソースコードからインストールしました。
pg_wait_sampling (GitHub - postgrespro/pg_wait_sampling: Sampling based statistics of wait events) の 2022/09/24 時点での最新版をインストールしました。
デフォルト設定との差分を以下に示します。
shared_buffers = 2GB effective_cache_size = 6GB maintenance_work_mem = 512MB checkpoint_completion_target = 0.9 wal_buffers = 16MB default_statistics_target = 100 random_page_cost = 1.1 effective_io_concurrency = 200 work_mem = 10485kB min_wal_size = 2GB max_wal_size = 8GB max_worker_processes = 4 max_parallel_workers_per_gather = 2 max_parallel_workers = 4 max_parallel_maintenance_workers = 2 autovacuum = off shared_preload_libraries = 'pg_wait_sampling'
検証スクリプト
概要は以下のとおりです。
- pgbench のクライアント数およびワーカスレッド数を 1 - 24 まで変化させる
- pgbench は 180 秒実行する
- pgbench 実行から 60 秒後に vmstat, iostat を 60 秒間計測する
- pgbench 実行中の待機イベントを pg_wait_sampling で集計する
通常パターンを計測する際のスクリプトを提示します。
#!/bin/bash
for cnum in `seq 1 24`
do
echo "${cnum} の実行です。"
pgbench -i -s 32 testdb
psql -d testdb -c 'SELECT pg_wait_sampling_reset_profile();'
pgbench -c ${cnum} -j ${cnum} -T 180 testdb >> pgbench_normal_${cnum}.txt &
pid_pgbench=${!}
sleep 60
vmstat 60 2 >> pgbench_normal_${cnum}.txt &
pid_vmstat=${!}
iostat -x 60 2 >> pgbench_normal_${cnum}.txt &
pid_iostat=${!}
wait ${pid_pgbench} ${pid_vmstat} ${pid_iostat}
psql --csv -d testdb -c "SELECT ${cnum} AS cnum, event_type, event, SUM(count) AS sum_event FROM pg_wait_sampling_profile WHERE event IS NOT NULL GROUP BY event_type, event ORDER BY sum_event desc;" >> pgbench_normal_wait_profile.txt
done
検証パターン
以下のパターンで検証します。
- 通常パターン (normal)
- 先に例示したスクリプトを用います。
- unloggedパターン (unlogged)
- pgbench で --unlogged-tables オプションを追加します。
- 非同期コミットパターン (asynchronous)
- postgresql.conf で synchronous_commit = off を指定します。
検証結果と考察
TPS や CPU の利用状況などは測定結果の一部を先述したため、ここでは割愛します。
各パターンでの待機イベントの傾向を確認します。サンプリングで現れることの多かった待機イベントが処理時間の多くを占めている(つまりボトルネック)と考えます。
特徴的な待機イベントを抜粋してグラフに表しています。
待機イベントの意味はマニュアルを参照しました。
28.2. 統計情報コレクタ

normal ではクライアント数に比例して LWLock:WALWrite が増加しています。この待機イベントは「WALバッファがディスクに書き込まれるのを待機しています」です。ここから、WAL 書き込みがボトルネックになっていると推測できます。
Lock:transactionid の増加も目立ちます。この待機イベントは「トランザクションが終了するのを待機しています」です。これは行ロック待ちで発生するようです。下記の記事を参考にしました。
トランザクションIDへのロックと行ロック
TPS に比例するように Client:ClientRead が増えています。この待機イベントは「クライアントからのデータの読み込みを待機しています」なので、TPS に比例するのは自然なことと考えられます。
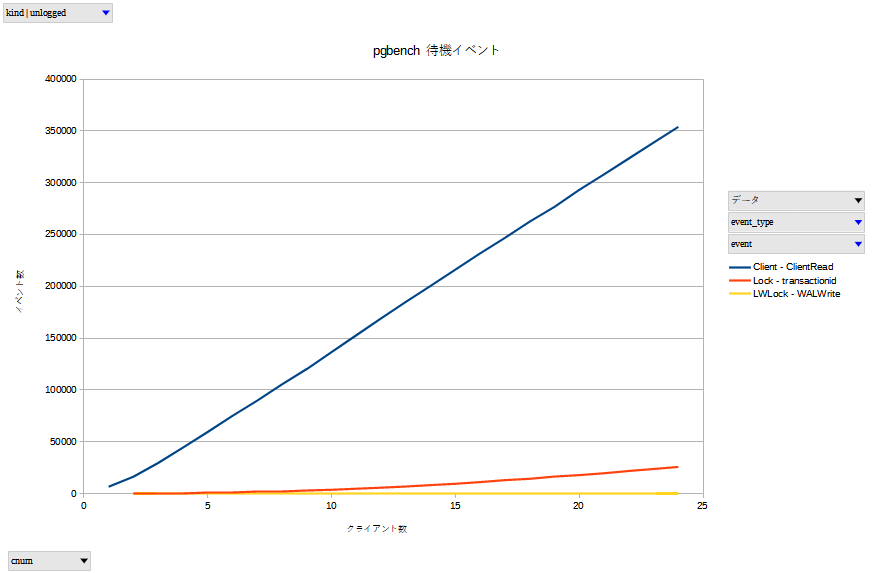
unlogged ではクライアント数に比例して Client:ClientRead が増加しています。このことから、大半の時間をクライアントからのデータ読み込みで待機していると推測できます。
なお、クライアント数に応じて Lock:transactionid が増加することは normal と同様です。
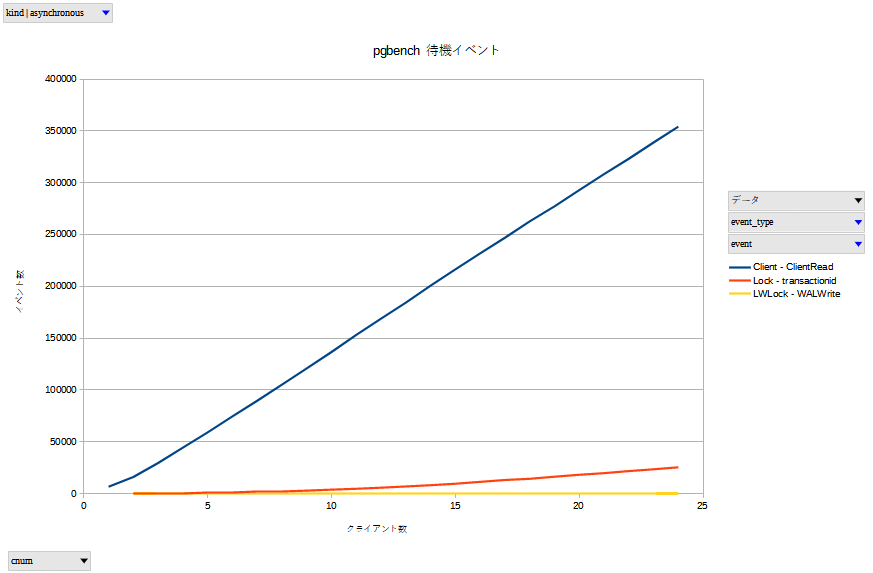
asynchronous は unlogged と同様の傾向にあることが読み取れます。
これらの結果により、normal では WAL 書き込みがボトルネックとなっていたと推測できます。
まとめ
今回の検証では待機イベントの情報収集手段として、pg_wait_sampling を利用しました。pg_wait_sampling を本番環境で後から導入することは難しいかもしれません。ですが、待機イベントの情報は pg_stat_activity ビューの wait_event_type, wait_event 列で確認できます。また、これを定期的に取得することで傾向を確認できます。
ボトルネックの調査手法の一つとして、待機イベントに着目するという手段が使えそうです。