概要
PostgreSQL の共有メモリバッファにはテーブルのデータだけでなく、インデックスのデータが含まれています。そこで、共有メモリバッファサイズがインデックスの更新に与える影響を検証及び考察しました。
検証環境
Windows の Hyper-V による仮想マシンを検証環境としました。
ホスト
| プロセッサ | Intel Core i5-6600 CPU @ 3.30GHz |
| メモリ | 20.0 GB |
| SSD | SanDisk SDSSDH3 |
| OS | Windows 10 Pro バージョン 1909 |
Hyper-V
| プロセッサ | 4個の仮想プロセッサ |
| メモリ | 8.0 GB |
| OS | CentOS Linux release 8.2.2004 |
| DB | PostgreSQL 13.1 |
検証方法
以下の条件を組み合わせて測定を行いました。
- shared_buffers の設定値
- 128MB, 2048MB
- B-tree インデックスの数
- 0~5 の範囲
- 格納値(テーブルの列に挿入する値)
- 昇順・降順・固定値・ランダム
実行時間は EXPLAIN の Execution Time で測定しました。
バッファの使用状況は EXPLAIN の出力で INSERT ノードに出力された値を参照しました。
インデックス5個でのスクリプト例を挙げます。
CREATE TABLE tab1 (col1 INTEGER, col2 INTEGER, col3 INTEGER, col4 INTEGER, col5 INTEGER); CREATE INDEX tab1_col1_index ON tab1 (col1); CREATE INDEX tab1_col2_index ON tab1 (col2); CREATE INDEX tab1_col3_index ON tab1 (col3); CREATE INDEX tab1_col4_index ON tab1 (col4); CREATE INDEX tab1_col5_index ON tab1 (col5); BEGIN; SELECT 'index = 5'; -- 以下のいずれかを実行する。 -- 昇順 EXPLAIN (ANALYZE, BUFFERS) INSERT INTO tab1 SELECT val, val, val, val, val FROM generate_series(1, 10000000) val; -- 降順 EXPLAIN (ANALYZE, BUFFERS) INSERT INTO tab1 SELECT (10000000 - val), (10000000 - val), (10000000 - val), (10000000 - val), (10000000 - val) FROM generate_series(1, 10000000) val; -- 固定値 EXPLAIN (ANALYZE, BUFFERS) INSERT INTO tab1 SELECT 1, 1, 1, 1, 1 FROM generate_series(1, 10000000); -- ランダム SELECT setseed(0); EXPLAIN (ANALYZE, BUFFERS) INSERT INTO tab1 SELECT random.val, random.val, random.val, random.val, random.val FROM (SELECT floor(random() * 10000000) val FROM generate_series(1, 10000000)) random; COMMIT; DROP TABLE tab1;
検証結果

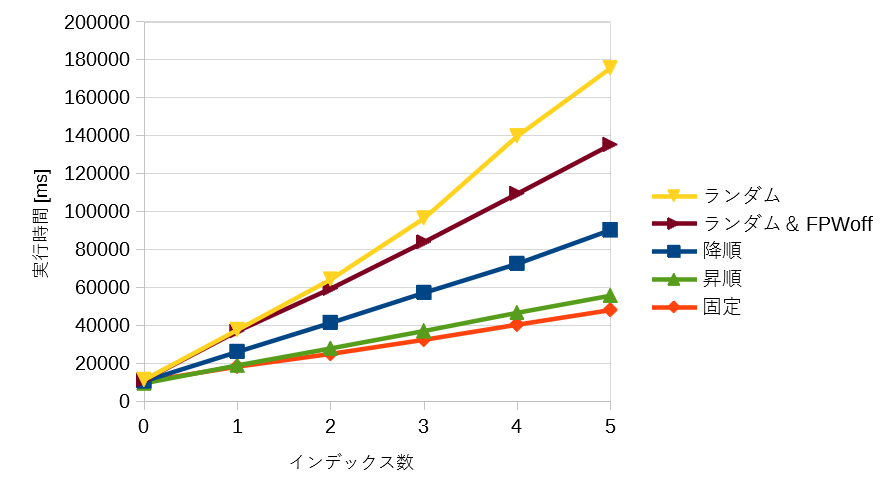
<図1 shared_buffers = 128MB 実行時間>

<図2 shared_buffers = 2048MB 実行時間>

<図3 shared_buffers と実行時間>
shared_buffers = 128MB での実行結果(図1)を見ると、ランダムな値を INSERT した時でインデックスが増えるに従い、実行時間が指数関数のような増加を描いています。インデックスの中身は同じであるので、shared_buffers = 2048MB での実行結果(図2)のような線形に近い増加となることを期待していました。
shared_buffers 設定値の違いは実行時間の違いとしても現れます。インデックス数 = 5・ランダム値で shared_buffers の値を変えて実行した結果が図3となります。実行時間が大きく異なっています。
この結果を考察します。
まず、インデックスのデータは共有メモリバッファに読み込まれます。
共有ブロックには、通常のテーブルとインデックスからのデータが含まれます。
EXPLAIN
また、ランダムな値でのインデックス更新は幅広い範囲のリーフページにアクセスします。
the values are not sequential at all, in fact each insert is likely to touch completely new leaf index leaf page (assuming the index is large enough).
On the impact of full-page writes - 2ndQuadrant | PostgreSQL
十分な共有メモリバッファが無いとき、更新対象となるインデックスデータの一部しか共有メモリバッファに展開できず、処理の進捗に応じてデータの入れ替えが都度発生し、パフォーマンスに影響が出ると推測されます。
検証結果で言えば shared_buffers = 128MB・ランダムのケースがそれにあたります。ランダムな値によるインデックス更新は幅広い範囲のリーフページにアクセスが必要、つまり更新対象となるインデックスデータの範囲が広い(サイズが大きい)ということになります。これに対して十分な共有メモリバッファが無いとデータの入れ替えが発生し、実行時間悪化につながったと考えられます。
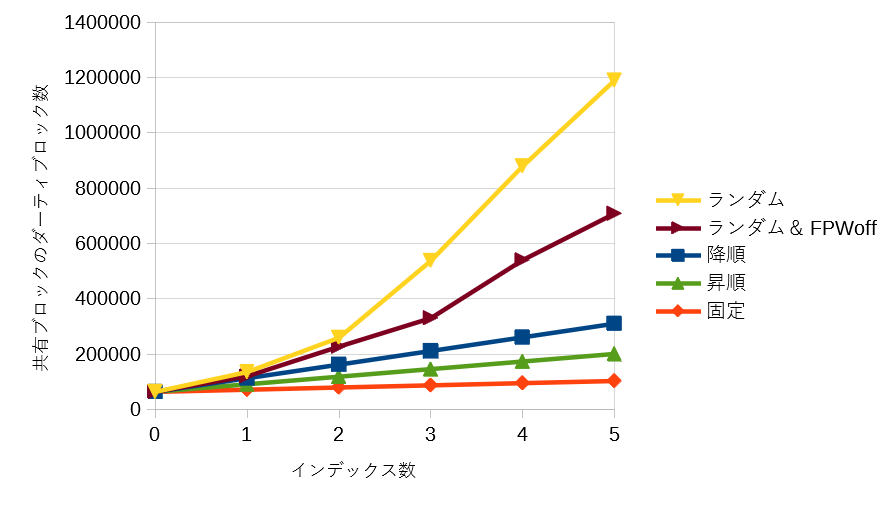
共有メモリバッファの使用状況でも特徴が表れていました。
| shared_buffers[MB] | index | shared hit | read | dirtied | written |
|---|---|---|---|---|---|
| 128 | 0 | 10,127,370 | 17 | 63,695 | 102,213 |
| 128 | 1 | 38,521,264 | 1,557,291 | 1,663,475 | 1,705,449 |
| 128 | 2 | 61,878,755 | 8,150,968 | 8,296,359 | 8,293,007 |
| 128 | 3 | 83,751,346 | 16,229,545 | 16,418,695 | 16,317,232 |
| 128 | 4 | 105,068,771 | 24,863,288 | 25,089,897 | 24,692,005 |
| 128 | 5 | 126,006,686 | 33,876,541 | 34,155,565 | 32,979,050 |
| 2048 | 0 | 10,127,370 | 17 | 63,695 | 63,695 |
| 2048 | 1 | 40,078,537 | 18 | 135,356 | 96,107 |
| 2048 | 2 | 70,029,704 | 19 | 259,384 | 128,519 |
| 2048 | 3 | 99,980,871 | 20 | 537,166 | 160,931 |
| 2048 | 4 | 129,932,038 | 21 | 879,378 | 193,343 |
| 2048 | 5 | 159,883,205 | 22 | 1,189,253 | 225,755 |
<表1 shared_buffers と共有メモリバッファ使用状況>
特に読み取り数 (read) の値が顕著に異なります。EXPLAIN ANALYZE のマニュアルで読み取り数の明確な定義はなされていませんが、共有メモリバッファへ読み込まれたブロック数を意味していると思われます。このように考えると、共有メモリバッファのデータの入れ替えが発生し、読み取り数の違いとして現れたのではないかと推測できます。
まとめ
今回の検証から以下のことが分かりました。
- インデックス数の増加は共有メモリバッファの占有率も増加させる。
- インデックスに格納される値の傾向が共有メモリバッファの占有率に影響する。
インデックスと共有メモリバッファサイズの関係は大量のデータを追加・更新する場面で特に影響を受けます。
実際の環境での共有メモリバッファの状況は動的であり、その時々で左右されます。また、共有メモリバッファにどれだけメモリを割り当てられるかはリソースとの兼ね合いもあり、調整は難しいかもしれません。
不要なインデックスを削除することが実効的な影響緩和策といえそうです。